Cramer's rule
Why does replacing one column of A reveal one solution coordinate?
Cramer's rule expresses each component of the solution to Ax = b as a determinant ratio. This chapter derives the formula algebraically, explains the signed-volume geometry in ℝ³ and ℝⁿ, then looks at what the same determinant-ratio picture says for rank-deficient inconsistent and consistent systems.
Key ideas
Cramer's rule turns coordinates into ratios of determinants.
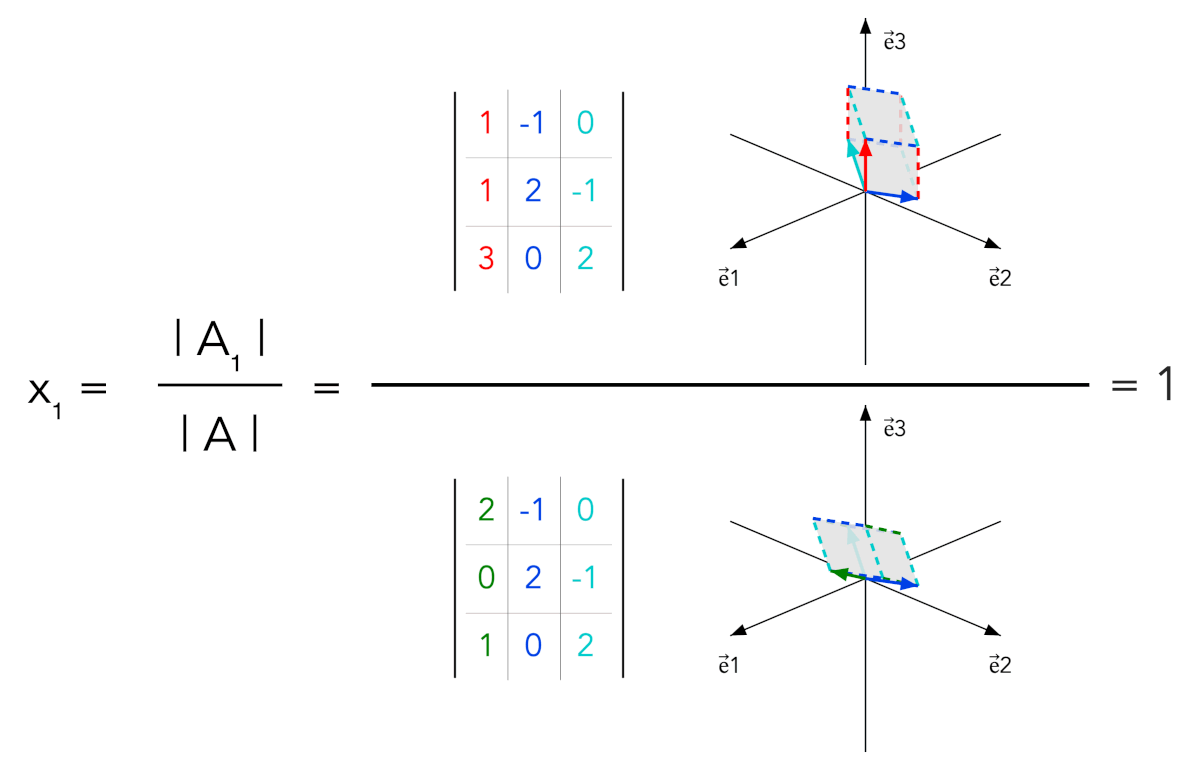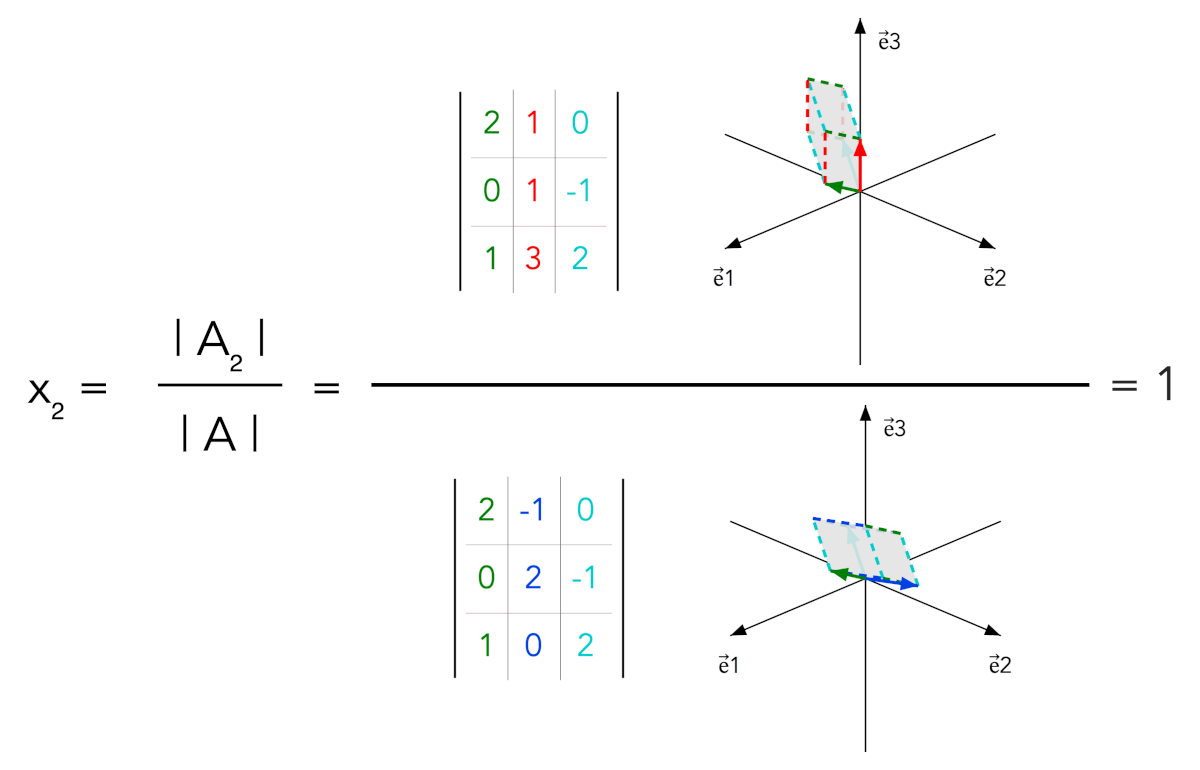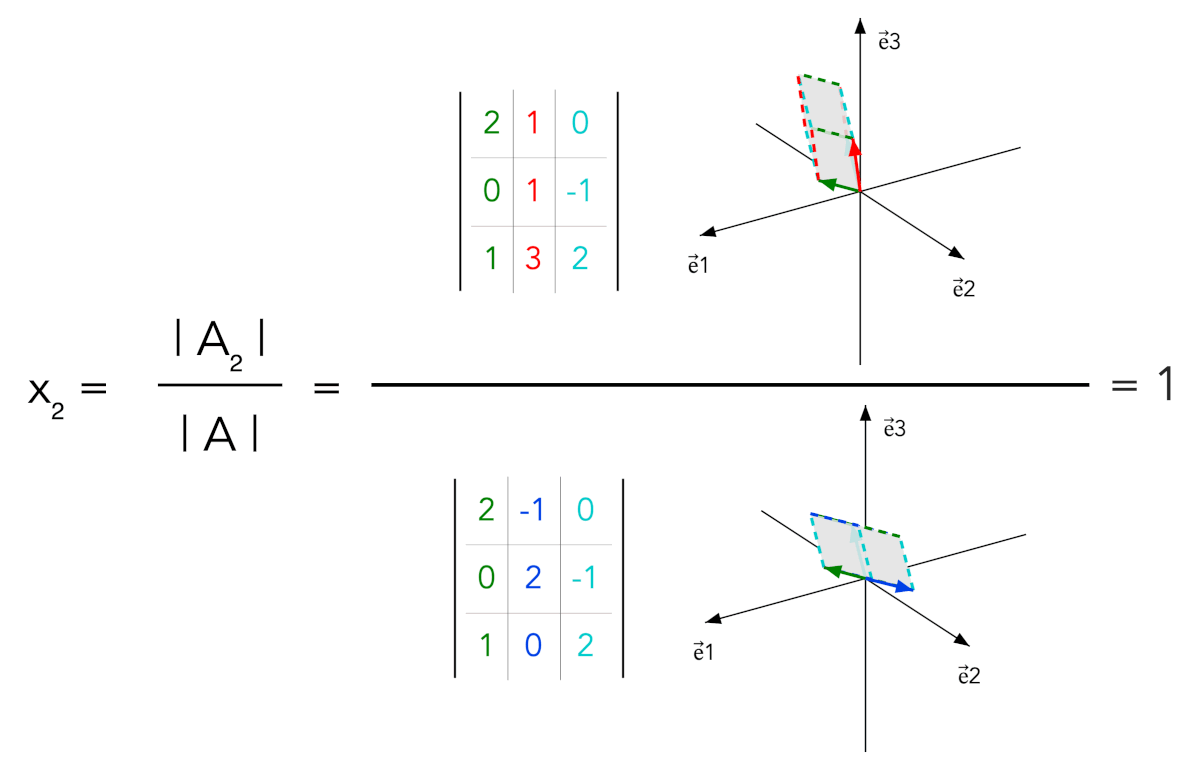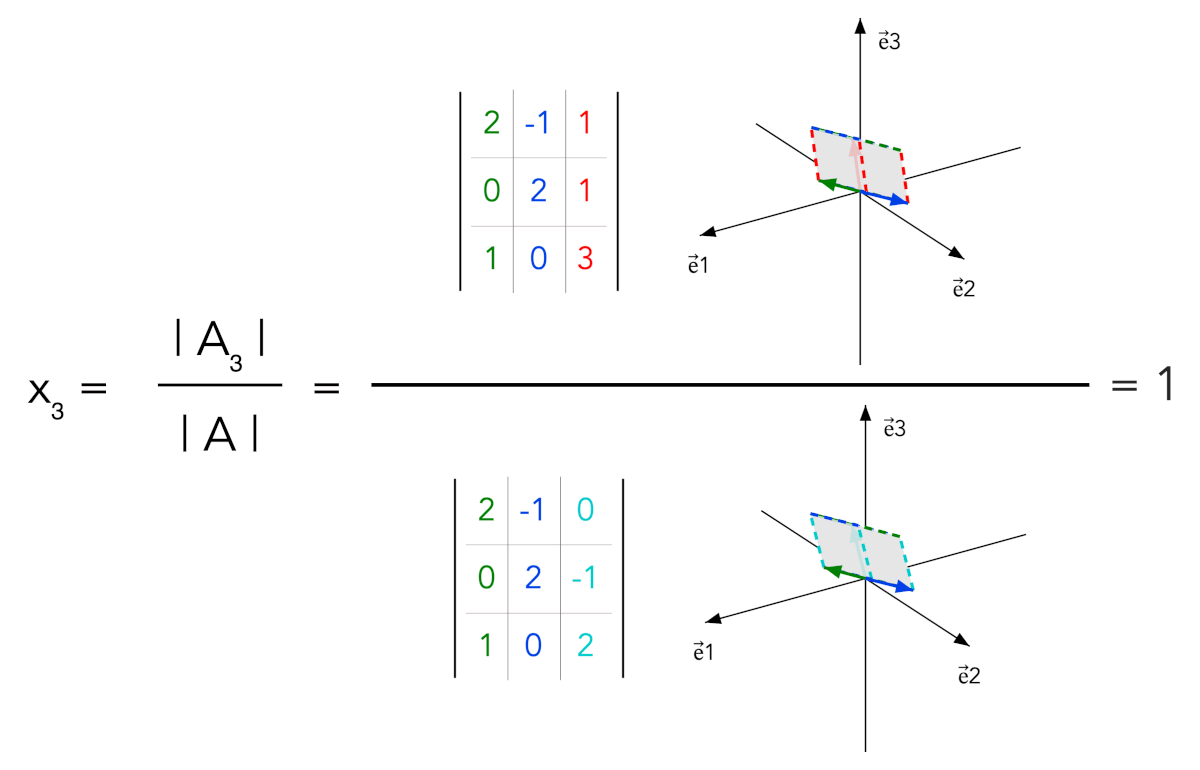
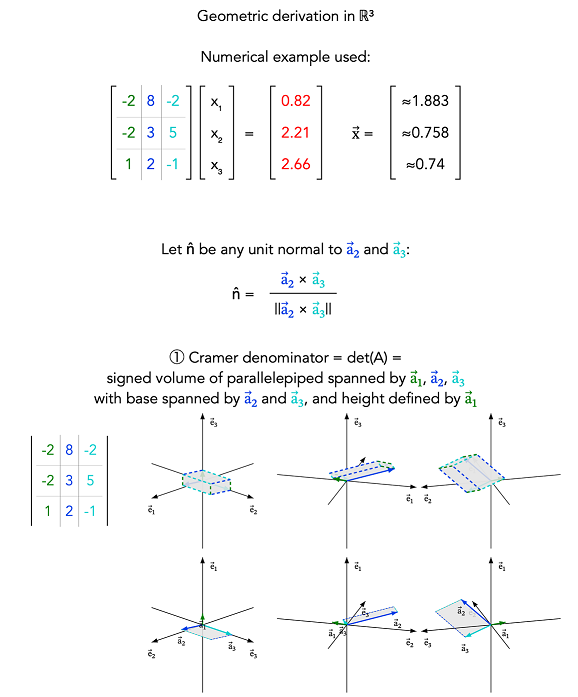
- For a square full-rank matrix A, each solution component xk is given by |Ak| / |A|
- The numerator matrix Ak is obtained from A by replacing column k with b
- The algebraic derivation builds a matrix Ck with det(Ck) = xk and uses |A Ck| = |A| |Ck|
- In ℝ³, the ratio can be read as a ratio of signed heights over the same base, or equivalently signed volumes
- In ℝⁿ, the same idea uses the hyperplane spanned by all columns except ai and a normal direction to that hyperplane
- If |A| = 0, the usual Cramer ratio is not defined, but the determinant/area picture still explains inconsistent and consistent rank-deficient behavior
The visual sections show how determinant ratios behave in full-rank 3D systems and what changes when the denominator volume collapses to zero.
Why does replacing one column isolate one coordinate?
In the full-rank case, b can be written uniquely as x₁a₁ + ⋯ + xₙaₙ. When column k is replaced by b, determinant multilinearity keeps only the term containing xkak; all other terms have repeated or dependent columns. Thus |Ak| = xk|A|.
Related chapters
Examples with visualizations
Cramer's rule in 3D
Animated determinant ratios and sign interpretation for x₁, x₂ and x₃
Why Cramer's rule works
Geometric derivation in ℝ³ and ℝⁿ using signed volumes and determinant ratios
Chapter contents
The PDF is a single document. The page links below are best-effort: most browsers support them, but some viewers may ignore the page hint.
What changes when A is rank-deficient?
Then |A| = 0, so the usual Cramer ratio is not defined. If b is outside col(A), the denominator volume is zero while some numerator volumes are nonzero, indicating inconsistency. If b lies in col(A), the numerator and denominator triples are all flat; the solution family can then be described by area ratios inside the common plane.